該模型可通過多個層面,考研市面上主流的中文 GPT 大模型的能力:
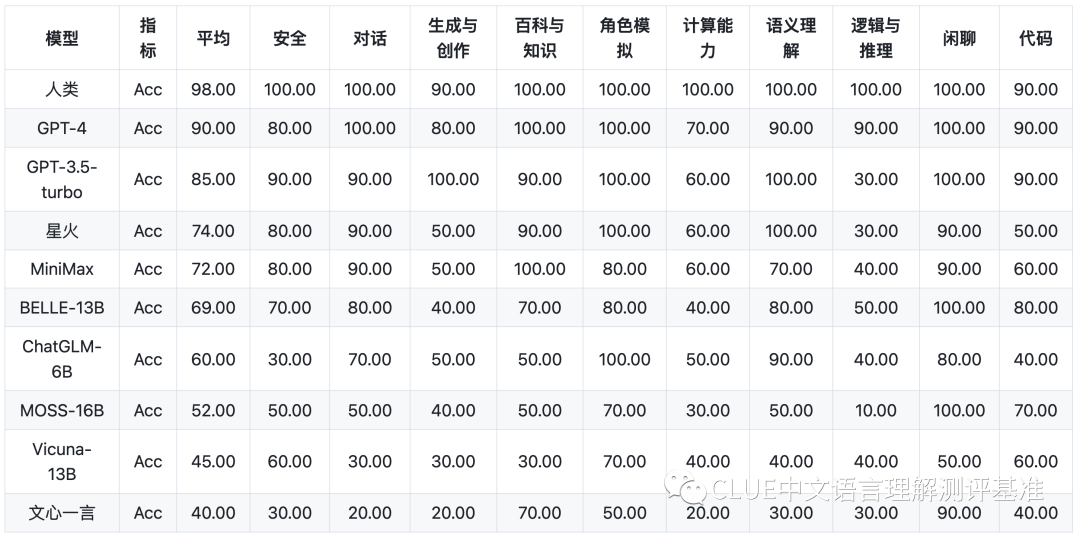
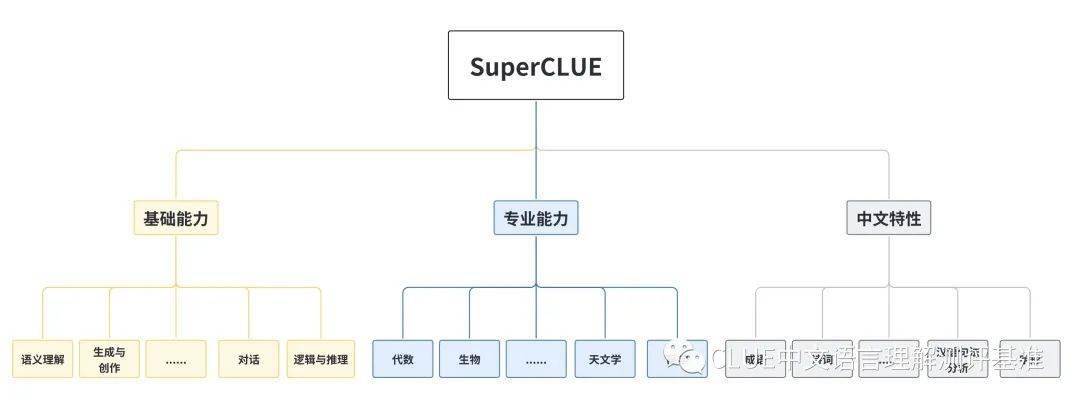
基礎(chǔ)能力: 包括了常見的有代表性的模型能力,如語義理解、對話、邏輯推理、角色模擬、代碼、生成與創(chuàng)作等 10 項(xiàng)能力。
專業(yè)能力: 包括了中學(xué)、大學(xué)與專業(yè)考試,涵蓋了從數(shù)學(xué)、物理、地理到社會科學(xué)等 50 多項(xiàng)能力。
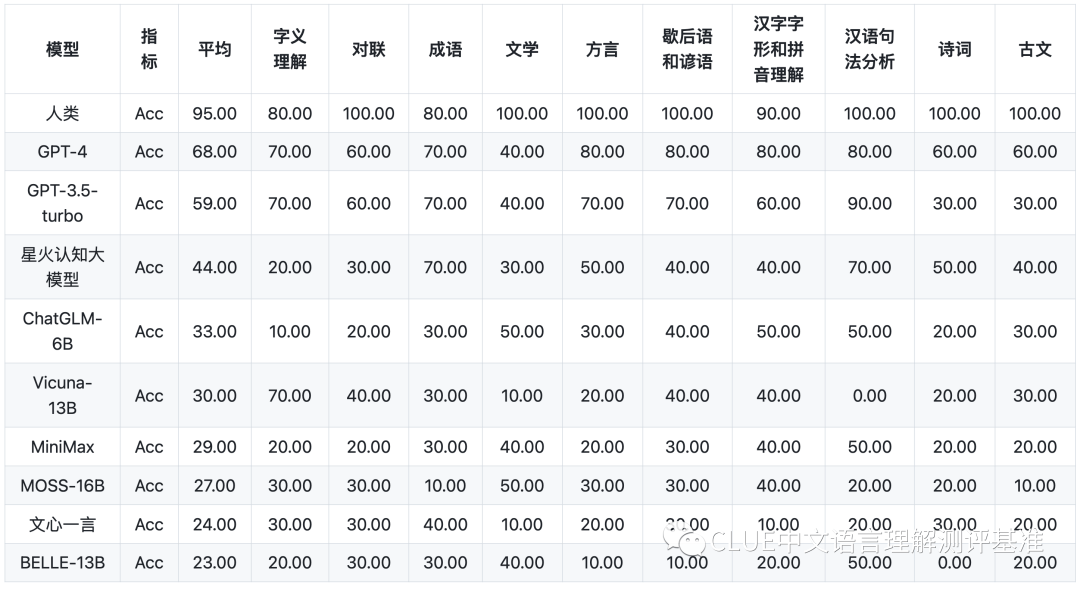
中文特性能力: 針對有中文特點(diǎn)的任務(wù),包括了中文成語、詩歌、文學(xué)、字形等 10 項(xiàng)多種能力。
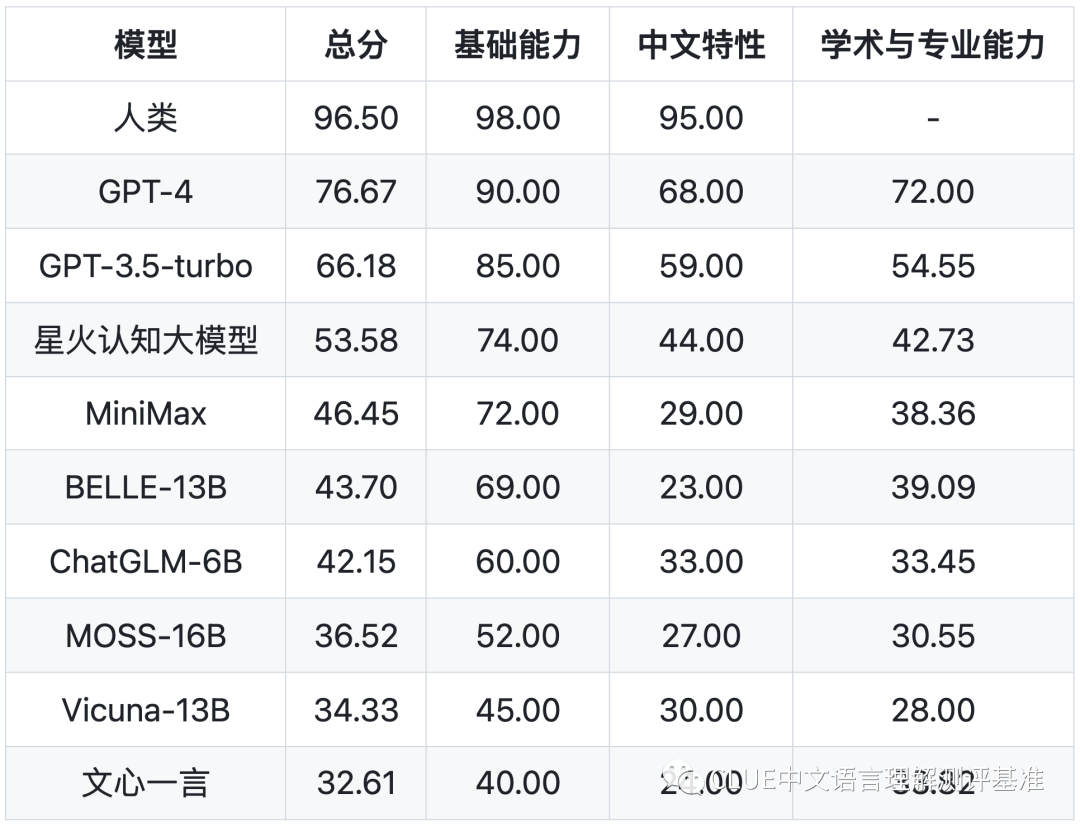
該機(jī)構(gòu)利用 SuperCLUE 測試基準(zhǔn),對市面上主流的支持中文的通用大模型進(jìn)行了評測與排名。從排名中我們可以看出,GPT-4 一騎絕塵,已經(jīng)非常接近人類的能力。國產(chǎn)大模型中訊飛科技研發(fā)的星火認(rèn)知大模型總排名第三,國內(nèi)排名第一。
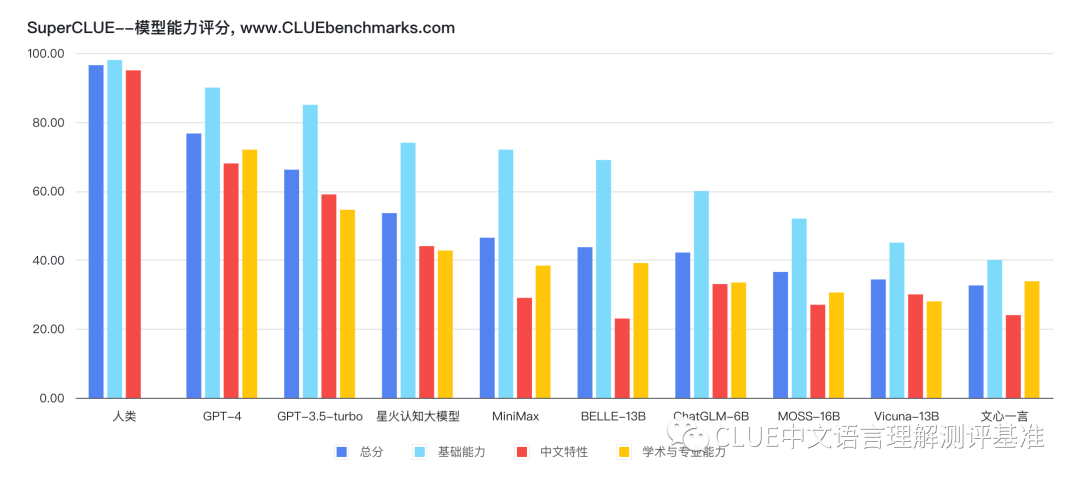
以下為該機(jī)構(gòu)公布的各個子項(xiàng)目的具體得分。排行榜會定期更新,并于以下網(wǎng)站進(jìn)行公示。CLUEbenchmarks 官方網(wǎng)站